新智元报道
编辑:Aeneas
【新智元导读】Scaling Law撞墙了吗?OpenAI高级研究副总裁Mark Chen正式驳斥了这一观点。他表示,OpenAI已经有o系列和GPT系列两个模型,来让模型继续保持Scaling。
最近,OpenAI高级研究副总裁Mark Chen在炉边谈话中,正式否认「Scaling Law撞墙论」。
他表示,并没有看到Scaling Law撞墙,甚至OpenAI还有两个范例——o系列和GPT系列,来保持这种Scaling。
用他的话说,「我们准确地掌握了需要解决的技术挑战」。

o1不仅是能力提升,也是安全改进
从经济角度看,OpenAI已经是最有价值的科技公司之一,因为他们为真实用户提供了数十亿美元的价值。
两年前,AI最前沿的任务还是小学数学题;而今天,它们已经可以做最难的博士生题目。
因此,我们正处于这样一个阶段:AI模型能够解决人类有史以来最困难的考试。
一旦这些模型解决了博士级别的问题,下一步,即使为世界提供实用性和价值。
当所有基准测试饱和之后,需要考虑的就是是否为最终用户提供了价值。
虽然今天AI通过了基准测试,但它并没有完全捕捉到AGI应该做的事。
好在,在过去一年里,OpenAI内部发生了最令人兴奋的进展——o1诞生了。
这不仅是一种能力上的提升,从根本上来说也是一种安全改进。
为什么这么说?
想象我们试图对一个模型进行越狱,旧的GPT系统必须立即做出回应,所以可能更容易被触发。
但当我们有一个推理器时,模型却会反思:这个问题是不是试图让我做一些与我要做的不一致的事?
此时,它获得的额外思考和反思的时间,会让它在很多安全问题上更稳健。
这也符合OpenAI研究者最初的预期。
当我们谈到推理时,这是一个广泛的概念,不仅仅用于数学或编程。
在编程中使用的推理方法,可能也适用于谈判,或者玩一个很难的游戏。
而说到基准测试,在安全性上也有同样的挑战。
安全性有点类似于这种对抗性攻击框架。在这种情况下,攻击是非常强烈的,因此我们在这方面还有很长的路要走。
如何到达五级AGI
AGI从一级到五级,关键推动因素是什么呢?
OpenAI提出的框架中,定义了AGI的不同级别,具体来说,就是从基本推理者发展到更智能的系统,再到能在现实世界里采取行动的模型,最终到达更自主、完全自主的系统。

在这个过程中,稳健性和推理能力是关键。
今天我们还不能依赖很多智能体系统,原因是它们还不够可靠。这就是OpenAI押注推理能力的原因。
OpenAI之所以大量投资,就是对此极有信心:推理能力将推动可靠性和稳健性。
所以,我们目前正处于哪一阶段呢?
OpenAI研究者认为,目前我们正从第一阶段向第二阶段过渡,朝着更智能系统的方向发展。
虽然目前,许多智能体系统仍然需要人类监督,但它们已经变得越来越自主。模型可以自行原作,我们对于AI系统的信任也在逐渐增加。
合成数据的力量
合成数据,就是不由人类直接产生的数据,而是模型生成的数据。
有没有什么好的方法,来生成用于训练模型的合成数据呢?
我们在数据稀缺或数据质量较低的数据集中,可以看到合成数据的力量。
比如,在训练像DALL-E这样的模型时,就利用了合成数据。

训练图像生成模型的一个核心问题是,当我们去看互联网上带标题的图片时,标题和它所描述的图片之间通常关联性很低。
你可能会看到一张热气球的照片,而标题并不是描述气球本身,而是「我度过最好的假期」之类的。
在OpenAI研究者看来,在这种情况下,就可以真正利用合成数据,训练一个能为图片生成高保真标题的模型。
然后,就可以为整个数据集重新生成捕获了,OpenAI已经证明,这种方法非常有效。
数据集中某方面较差的其他领域,也可以采用这个办法。
Scaling Law没有撞墙
最近很火热的一个观点是,Scaling Law已经撞墙了,许多大型基础实验室都遇到了预训练的瓶颈。
果真如此吗?
Mark Chen的观点是,虽然的确在预训练方面遇到一些瓶颈,但OpenAI内部的观点是,已经有了两种非常活跃的范式,让人生成无限希望。
他们探索了一系列模型的测试时Scaling范式,发现它们真的在迅速发展!
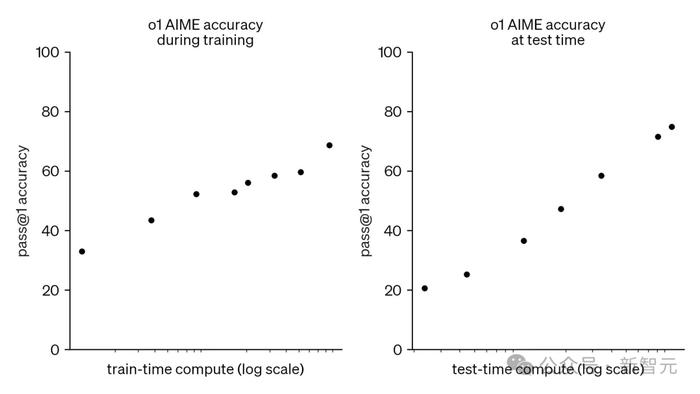
在推理模型的Scaling上,也没有同样的障碍。
其实,从早期入职OpenAI后,研究者就一直遇到多个技术挑战。现在这些挑战已经非常具体,在Mark Chen看来,没有什么是完全无法应对的。
在OpenAI内部,大家经常说推理范式已经达到了一定的成熟度。有些产品已经有了与市场的契合点,虽然进展仍然非常缓慢。
过去几周内,最令人惊讶的使用场景,莫过于和o1进行头脑风暴了。
o1和GPT-4的对比,让人感受到了全新的深度:人类仿佛终于有了一个真正能互动的陪练伙伴,而非仅仅对自己的想法进行评论。
它仿佛一个真正的实体,非常有参与感。
o1的推理直觉,是如何产生的
OpenAI的研究者,是如何想到o1中的推理直觉的呢?
这是一个集体努力的结果,不过他们也进行了很长时间的工作,进行了一些探索性的重点尝试。
在两年前,他们就觉得,AI虽然非常聪明,但在某些方面是不足的。不知为什么,总是感觉不太像AGI。
当时他们假设,原因在于,这是因为AI被要求立即做出回应。
就算我们要求一个人类立即做出回应,ta也未必能给出最好的答案。
一个人可能会说,我需要思考一会,或者我需要做一些研究,明天再答复你。
就在这里,OpenAI研究者发现了亮点!
其实这里缺少的,是连接系统一和系统二之间的鸿沟。
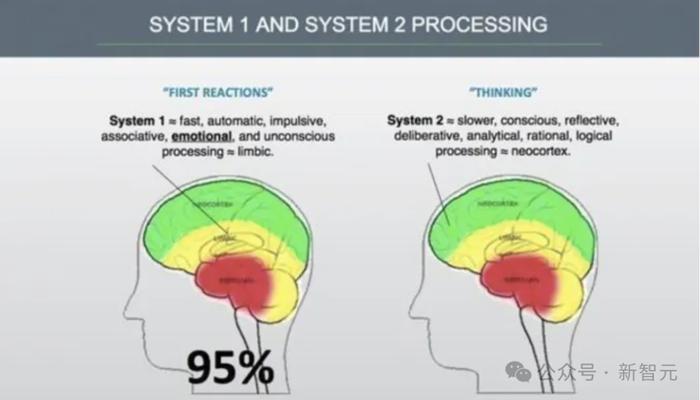
快速思考有,知识也有,但却没有慢速思考,核心假设就在这里。
研究者做了许多不同尝试,来解决这个挑战。
一群非常具有探索精神的研究者,获得了一些生命迹象。
围绕这些迹象,他们组建了研究团队,扩大的项目规模,投入了大量的数据生成工作。
从快速进展中获取预测结果,是整个案例中最难的部分。
开始时,就像登月计划一样,会遭遇很多失败。
有三四个月,他们完全没取得多少有意义的进展。
好在最终,总会有人获得重大突破。这也就给了他们足够的动力来投入更多资源,往前推动一点。
从o1推出几个月后,OpenAI和许多外部合作伙伴进行了交流。
最酷的一件事就是,他们发现它比使用微调方法要好得多——它已经不太容易被问题难倒了。
很多应用已经超出了研究者之前关注的数学和科学领域。当看到AI的推理能力能泛化到这些领域,真的令人惊喜。
比如在医学领域,模型在医学症状的判断上,涉及形成假设、验证,随后再形成新的假设。
即使在研究者没有特别关注的领域,模型也进展得很快,比如医学、法律推理。
而他们也确信,在未来还会有其他还未测试过的领域,AI会有重大进展。
OpenAI仍然注重安全
Mark Chen肯定地说,目前OpenAI仍然像早期那样,致力于研究和安全。
为此,他管理着一个非常庞大的研究项目组合。并且一直在思考着应该分配多少资源和力量来进行探索性研究,而不是短期的即时项目。

不过,在这方面,OpenAI和很多大型基础实验室不同。
这些大实验室有很多优秀的研究者,可以没有方向地进行研究,自由地去做任何事。
但对OpenAI来说,他们比这些实验室的规模都要小,因此需要更有方向性。
他们选择了一些非常有信心的探索性项目,在这些领域内,给了研究者很大的自由度。
也就是说,OpenAI并不会进行毫无目标的探索,而且充分利用了自己规模小的优势。
现在是AI创业的好时机
OpenAI的研究者也认为,现在是基于AI创立初创公司的好时机。
基础模型的玩家专注的是通用性。
但像OpenAI这样的公司,不可能涉足每一个垂直领域。
在特定领域定制一个模型,有很多空间和可能性。
现在,我们已经可以看到一个丰富的初创企业生态系统,这些企业在OpenAI的基础上构建了各种类型的应用。
通常情况下,初创企业之所以能够成功,是因为他们知道并坚信某个秘密,而市场上的其他人并不知道这个秘密。
在AI领域,实际上就是在一个不断变化的技术栈上进行构建,我们无法预测下一个模型会何时出现。
表现最好的初创企业,就是那些有直觉,在刚刚开发发挥作用的边缘技术上进行构建的企业,它们有一种生命力。
当我们拥有AGI,就是相当强大的形式,真正释放了全部潜力。
想象一个人在一周内,就能创建一个带来巨大价值的大型初创公司。
一个人在几天内产生巨大影响的想法,已经不仅限于商业领域。
这种怀旧的感觉就像17世纪,科学家们在探讨物理学一样。
我们能否回到那种氛围,一个人能做出医学、物理学或计算机科学领域的重大发现?
而这些,都是因为AI。
参考资料:
https://x.com/tsarnick/status/1860458274195386658